

이 블로그에서는 두 가지 커스텀 loss function과 XGBoost 패키지로 median regression 을 수행하는 방법을 배워보겠다.
왜 median regression 이 유용한걸까?
least squares loss 함수는 가장 널리 사용되는 오류 측정법이며 대부분의 경우에 충분하다. 그러나 데이터에 outlier가 있는 경우, least squares loss 함수를 사용하는 것은 적절하지 않을 수 있다. outlier가 존재할 때 우리에게는 2가지 선택 사항이 있다. 첫째, outlier를 정의하고 이를 제거한 후에 least squares loss를 사용하려고 시도할 수 있다. 두 번째로, outlier를 유지하고 robust loss, 즉 median loss을 사용할 수 있다. 따라서 median loss를 사용하면, 우선, 우리는 outlier를 정의할 필요가 없으며 (지저분한 실생활 데이터에서 이는 정의하기 매우 까다로울 수 있다). 둘째, 어떤 데이터도 잃을 필요가 없다.
robust loss 함수란 무엇일까?
robust loss 함수는 outlier의 영향을 받지 않는 loss 함수이다. robust loss의 가장 기본적인 예는 mean absolute loss 또는 L1 손실이다. 그러나 불행히도 우리는 L1 손실을 사용하여 XGBoost 알고리즘을 최적화할 수 없다. 그 이유는 XGBoost가 최적화 과정에서 loss 함수의 2차 미분을 분모의 값으로 사용하는데 MAE의 2차 미분 값은 모든 곳에서 0이기 때문이다. 따라서 2회 연속 미분이 가능한 robust loss의 함수를 사용해야 한다. 이 블로그에서 볼 두 가지 robust loss 함수는 pseudo Huber loss 함수와 log cosh loss 함수이다.
Pseudo Huber loss 함수:


log Cosh loss 함수:
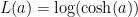
이 함수들을 시각적으로 L2과 비교하여 어떻게 다른지 살펴보고 왜 “robust”한지 알아 보자.
import numpy as np
import matplotlib.pyplot as plt
def pseudo_huber_loss(a, delta):
tmp = np.sqrt((a/delta)**2 + 1)
return delta**2 * (tmp - 1)
def l2_loss(a):
return a**2
def l1_loss(a):
return np.abs(a)
def log_cosh_loss(a):
return np.log(np.cosh(a))
x = np.linspace(-5, 5, 1000)
fig, ax = plt.subplots(figsize=(12, 8), num=1)
ax.set_xlabel('a', size=10)
ax.set_ylabel('loss', size=10)
ax.plot(x, l2_loss(x), label='L2 Loss')
ax.plot(x, pseudo_huber_loss(x, 0.25), label='Pseudo Huber Loss')
ax.plot(x, log_cosh_loss(x), label='Log Cosh Loss')
ax.plot(x, l1_loss(x), label='L1 Loss')
ax.legend()
보다시피, L2 손실은 오류의 크기가 커짐에 따라 패널티가 증가하는 반면, robust loss는 오류를 일정하게 처벌한다. 즉, 모델 최적화 단계에서 원점의 한 측면에 있는 모든 오류는 미분이 모두 같기 때문에 균등하게 처벌된다. 사실 연속 2차 미분이 가능하기 때문에 미분이 일정하지는 않다. 다만, 그 차이가 매우 작아서 일정한 것 같은 효과를 보는 것 뿐이다.
이러한 에러 함수를 사용하여 XGBoost 알고리즘을 최적화하려면 gradient와 hessian을 유도해야한다.
pseudo Huber loss gradient:

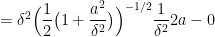
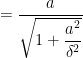
pseudo Huber loss hessian:



log cosh loss gradient:


log cosh loss hessian:


자 그럼, 위 함수들이 제대로 작동을 하는지 확인해 보자. 우리는 시각적 효과를 극대화하기 위해 아웃 라이어가 명백한 간단한 인공적인 데이터 셋을 사용하겠다. 실세계의 데이터 셋에서는 아웃 라이어를 정의하는 것은 배우 어려울 수 있음을 기억하자. L2 loss를 사용하는 XGBoost 모델은 아웃라이어에 의해 영향을 받는 반면, robust loss를 사용하는 XGBoost 모델은 아웃라이어에 전혀 영향을 받지 않는 것을 확인 할 수 있다.
X = np.arange(500).reshape(500, 1)
y = X + 5 + np.random.normal(0, 20, [500, 1])
y[300:500:30] = 5000
plt.scatter(X, y)
dtrain = xgb.DMatrix(X, label=y)
param = {'max_depth': 15, 'alpha':10, 'lambda':20, 'monotone_constraints': (1,-1,0)}
num_round = 250
model_squared_error = xgb.train(param, dtrain, num_round)
fig, ax = plt.subplots(figsize=(6, 4), num=1)
ax.set_ylim([0, 1200])
ax.scatter(X, y)
ax.plot(model_squared_error.predict(dtrain), c='red')
def huber_approx_obj(preds, dtrain):
a = preds - dtrain.get_label()
delta = 2
placeholder = 1 + (a / delta) ** 2
grad = a / np.sqrt(placeholder)
hess = 1 / placeholder / np.sqrt(placeholder)
return grad, hess
param = {'max_depth': 15, 'alpha':10, 'lambda':20, 'monotone_constraints': (1,-1,0)}
num_round = 250
model_huber_approx_obj = xgb.train(param, dtrain, num_round, obj=huber_approx_obj)
fig, ax = plt.subplots(figsize=(6, 4), num=1)
ax.set_ylim([0, 1200])
ax.scatter(X, y)
ax.plot(model_huber_approx_obj.predict(dtrain), c='red')
def log_cosh_obj(preds, dtrain):
a = preds - dtrain.get_label()
grad = np.tanh(a)
hess = 1 - np.tanh(a)**2
return grad, hess
param = {'max_depth': 15, 'alpha':10, 'lambda':20, 'monotone_constraints': (1,-1,0)}
num_round = 250
model_log_cosh_obj = xgb.train(param, dtrain, num_round, obj=log_cosh_obj)
fig, ax = plt.subplots(figsize=(6, 4), num=1)
ax.set_ylim([0, 1200])
ax.scatter(X, y)
ax.plot(model_log_cosh_obj.predict(dtrain), c='red')